小记正则(一)
0x00 什么是正则表达式
正则表达式是使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。 总之,正则表达式就是一个标记语法,简单的描述复杂的语言。比如匹配一个数字 4-6 次,正则就简单的表示为 [0-9]{4,6}。
0x01 常见的标记
可以在维基百科上查看正则常用标记。
0x02 浅谈贪婪和非贪婪
贪婪和非贪婪是正则语法中非常重要的两种模式,可以说没有这两老大哥,你不禁会感叹正则表达式也不过如此。
贪婪
尽可能多的去匹配某一种模式,遇到不匹配的然后进行回溯。
我们平时常见的贪婪模式有*, +, ?, {n,m}, {n,}, {n}。
贪婪的代价很大,假设我有如下的普通的字符串 44546, 我们使用 ^.*45 的正则表达式去匹配,执行流程将会如下:
- 正则 ^, 明白是以匹配方式开头,进行下一个正则
- 正则 .*,匹配 4
- 正则 .*,匹配 4
- 正则 .*,匹配 5
- 正则 .*,匹配 4
- 正则 .*,匹配 6
- 正则 .*, 发现字符串到尾部,不能匹配, 进行下一个正则
- 正则 4,发现字符串已经到尾部,往前回溯
- 正则 4,回溯到 6,不匹配,继续回溯
- 正则 4,回溯到 4,匹配,正则 5,不匹配 6,继续回溯
- 正则 4,回溯到 5,不匹配,继续回溯
- 正则 4,回溯到 4,匹配,正则 5,匹配 5,匹配成功
可以看见在这个过程中,.* 是一直匹配到最后一个不能的匹配的字符为止,然后往前回溯,匹配结果。这也正是贪婪的思想:尽可能多的去匹配。
回溯的最大长度等于贪婪匹配终点-贪婪匹配起点。
非贪婪
尽可能少的去匹配某一种模式。非贪婪的模式中,也会出现大量的回溯。
常见的开启贪婪的方式 *?, ??, +?, {n,m}?, {n,}?。
假设我们有如下的普通字符串 s=111114 , 我们用正则表达式 r=1{3,6}14 去匹配
- 正则 1,匹配 r[0]=1
- 正则 1,匹配 r[1]=1
- 正则 1,匹配 r[2]=1
- 达到匹配的下限,表示满足 1{3,6} 这个式子,开始跳过 1{3,6} 判断匹配 14
- 正则 1,匹配 r[3]=1
- 正则 4, 不匹配 r[4]=1, 回溯到 1{3,6}, 1{3,6}再多匹配一次1,然后回到 14
- 正则1,匹配 r[4]=1
- 正则4,匹配 r[5]=4
- 匹配结束
从整个匹配过程可以看出
- 首先要满足匹配的下限,如果下限满足不了,即表示不符合规则,再怎么尽可能少也不行
- 达到下限后,不急着继续匹配了,先判断后面模式的是否满足条件,如果不满足条件,则再多匹配一次模式,继续判断后面的模式,每次加一个
0x03 浅谈 |
在正则中我们会遇见 | ,这个记号,通常来匹配句子。比如 (ab | cd),表示ab或者cd。
但是 | 这个语句,如果不适当优化,也是容易出现大量的回溯。
一个很简单的例子:
用正则 aabb|aacb 来匹配普通字符串 r=aacb
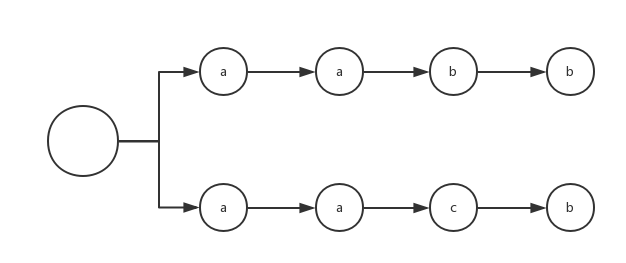
这个过程会先从aabb这条链出发
- 正则a,匹配 r[0] = a
- 正则a,匹配 r[1] = a
- 正则b,不匹配 r[2] = c ,回溯r到下标0,匹配另外一条链
匹配aacb这条链条, 这个时候r的下标又会从0开始
- 正则a,匹配 r[0] = a
- 正则a,匹配 r[1] = a
- 正则c,匹配 r[2] = c
- 正则b,匹配 r[3] = b
- 匹配结束
可以看出一条链进行失败,会切换到另外一条链,而且r的下标也会回溯到匹配开始的位置。
但是从图中来看, aa 是两条链的公共前缀,实际上应该从 aa 后面开始分叉,这样就可以有效减少回溯次数。
优化之后的正则表达式 aa(bb|cb)
0x04 小结
平时我们在写正则表达式的时候,应该了解其匹配原理,然后设计出一个经过优化的表达式。毕竟,你永远也想不到,.* 这种回溯会给你带来多大的影响😄。